"Information Gravity in Neural Networks: A Unified Framework for Computational Resource Allocation Across Inference, Attention, and Training
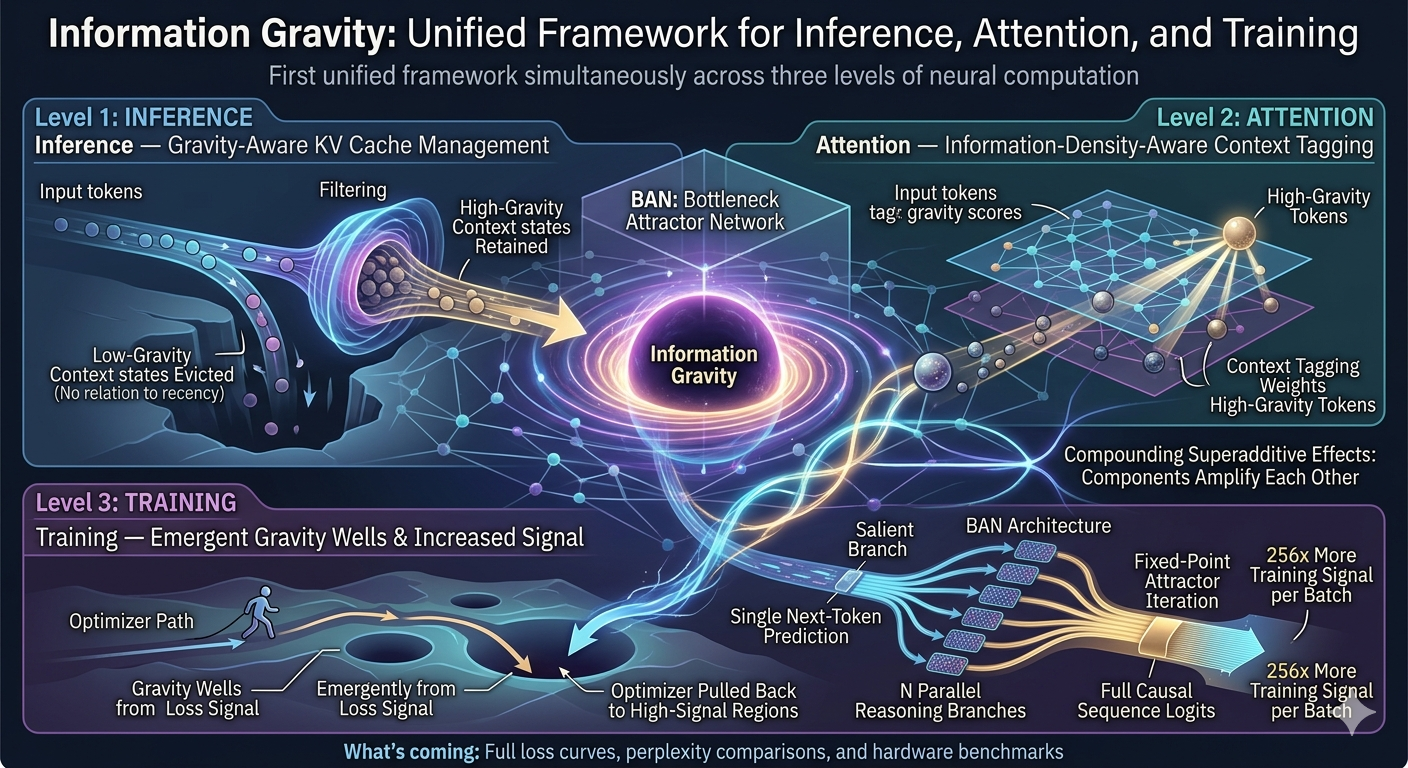
Information Gravity: A Novel Application to Neural Network Architecture and Training The paper establishes that information gravity — the principle that dense information regions attract computational resources — is not a new concept, but presents the first unified framework for applying it explicitly across all three levels of neural computation simultaneously. The three levels: Inference — KV cache scoring retains high-gravity context states, evicts low-gravity ones regardless of recency Attention — context tagging weights high-gravity tokens, making attention information-density-aware Training — gravity wells form emergently from the loss signal, pulling the optimizer back to high-signal regions without manual labeling or predefined importance functions The architecture — BAN: A from-scratch neural architecture built around these principles. Generates N parallel reasoning branches, scores them cheaply via salience, converges deeply on the best branch via fixed-point attractor iteration, while peripheral branches inform focus without overwhelming it. Outputs full causal sequence logits giving 256x more training signal per batch than single next-token prediction. The key finding: Applying information gravity at all three levels simultaneously produces compounding, superadditive effects. Components amplify each other. Empirical results during active training exceeded conservative theoretical predictions. What's coming: Training results addendum with full loss curves, perplexity comparisons, and hardware benchmarks once the current training run completes.